Acerca de EVIC
La XX Escuela de Verano en Inteligencia Computacional, es organizada conjuntamente por el Capítulo Chileno de la IEEE Computational Intelligence Society (CIS) y la Facultad de Ingeniería y Ciencias Aplicadas de la Universidad de los Andes..
La EVIC tiene como objetivo promover la Inteligencia Computacional, reuniendo áreas como Aprendizaje de Máquinas, Bioinformática, Robótica, Visión por Computador, Sistemas de Control Inteligente, Analítica de Negocios, Ciencia de Datos y Big Data, entre otras, con el fin de difundir los conocimientos básicos y los últimos avances en investigación a estudiantes, profesores y profesionales de Chile y otros países de Latinoamérica.
Concurso de
Posters
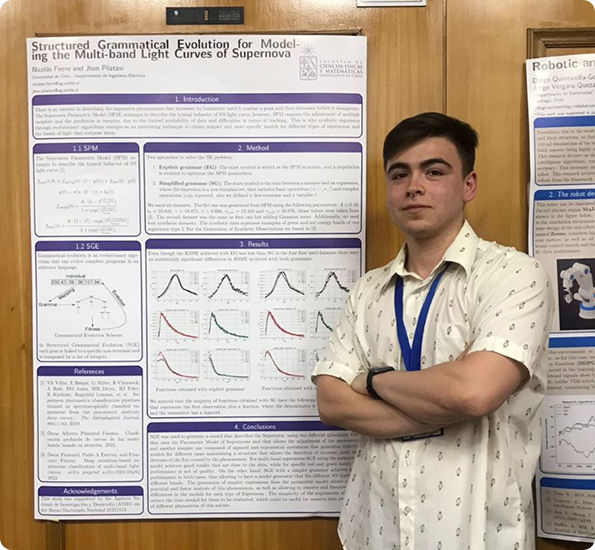
En el marco de EVIC 2025 se realizará un Concurso de Posters en Inteligencia Computacional. Esta competencia está dirigida a estudiantes o recién graduados. Para participar, los y las estudiantes deberán enviar un abstract extendido en idioma inglés.
Más informaciónInscripciones
Reserva tu cupo.
VALOR $30.000
VALOR $56.000
VALOR $68.000
VALOR $228.000
VALOR $96.000
Hacerse miembro de la IEEE CIS otorga un descuento
importante en el evento
Venue

Universidad de los Andes
La Escuela de Verano en Inteligencia Computacional (EVIC 2025) celebrará su vigésima versión en la Facultad de Ingeniería y Ciencias Aplicadas de la Universidad de los Andes, en Santiago de Chile. El evento se llevará a cabo en el edificio de Biblioteca de la Universidad.
Más informaciónOrganiza
Equipo Organizador Local
Carla Vairetti
José Delpiano
Matías Recabarren
Jorge Gómez
Pamela Bustamante
José Saavedra
Anelis Pereira.
Equipo Organizador Nacional
Sebastián Maldonado (Universidad de Chile)
Jorge Vergara (Universidad Tecnológica Metropolitana)
Pamela Guevara (Universidad de Concepción)
Claudio Held (Universidad de Chile)
Gonzalo Acuña (Universidad de Santiago de Chile).
Facultad de Ingeniería y Ciencias Aplicadas, Universidad de los Andes.

IEEE Computational Intelligence Society (CIS)

Instituto Sistemas Complejos de Ingeniería (ISCI)

Auspician